1、Java客户端版本概览
官网文档解读
Elasticsearch Version的版>=8.x ,官网地址:https://www.elastic.co/docs/reference/elasticsearch/clients/java

Elasticsearch Version的版<8.x,官网地址:
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.17/java-rest-high-javadoc.html
Transport Client迁移至REST Client
1、Transport Client随着Elasticsearch的第一个版本诞生,是一个特别的客户端。特别之处在于,它使用TCP协议与Elasticsearch通信,这也造成了当客户端与不同版本的Elasticsearch通信时,会存在兼容性问题。
2、Elasticsearch官网于2016年发布Low Level REST客户端,该客户端基于Apache HTTP客户端,允许通过HTTP协议与任何版本的Elasticsearch集群通信。在Low Level REST客户端的基础上,Elasticsearch发布了High Level REST Client。
3、Elasticsearch 7.0中已经弃用Transport Client,在8.0中完全移除它。因此在实际开发中建议您使用Java REST Client。REST Client通过HTTP请求,帮助您处理请求和返回的序列化问题,为您的业务开发带来便捷。
各客户端概述
1. TransportClient (已弃用)
类型: 原生 Java 客户端
状态: Elasticsearch 7.0 中已弃用,8.0 中完全移除
特点:
- 使用 Elasticsearch 的二进制传输协议
- 与集群保持长连接
- 需要与 Elasticsearch 服务器版本严格匹配
- 性能较高但耦合性强
2. Low-level REST Client (已弃用)
类型: RESTful HTTP 客户端
状态: 已被 High Level REST Client 取代
特点:
- 轻量级 HTTP 客户端
- 提供最基本的请求/响应功能
- 需要手动处理 JSON 序列化/反序列化
- 版本兼容性较好
3. High Level REST Client (官方推荐)
•类型: RESTful HTTP 客户端
•状态: 当前官方推荐客户端
•特点:
- 基于 Low-level REST Client 构建
- 提供更友好的 API 和对象映射
- 支持请求构建器和响应解析器
- 版本兼容性较好
- 7.15 后也被标记为弃用,推荐使用新的 Java API Client
4. Java API Client (官方推荐)
类型: RESTful HTTP 客户端
状态: 当前官方推荐客户端,自 Elasticsearch 7.16 / 8.0 版本起正式推出,旨在全面替代 High Level REST Client (HLRC)
特点:
1.API 优先,强类型化:客户端的所有方法、请求和响应对象都是通过 Elasticsearch 的 REST API 规范自动代码生成的。这意味着客户端与服务器的 API 定义完全同步,提供了编译时的类型安全。
2.永久的向后兼容性承诺:客户端与 Elasticsearch 服务器主版本号绑定(例如,8.13.0 的客户端对应 8.13.0 的服务器)。官方承诺,在同一主版本(如 8.x)内,老版本的客户端可以兼容新版本的服务器,且客户端的 API 不会出现破坏性变更。
3.清晰的架构分层:
- •底层 HTTP 客户端 (
elasticsearch-java):一个非常轻量、无状态的库,只负责 HTTP 通信和 JSON 序列化/反序列化。它支持多种 JSON 库(如 Jackson, JSON-B)。 - •上层领域客户端 (
ElasticsearchClient):包含所有 Elasticsearch 领域知识(如索引、搜索、聚合等),通过代码生成器产生,并依赖底层 HTTP 客户端。
- •底层 HTTP 客户端 (
5. Spring Data Elasticsearch
•类型: Spring 生态的集成模块
•状态: 活跃维护
•特点:
- 基于 High Level REST Client 或新的 Java API Client
- 提供 Repository 抽象和模板模式
- 与 Spring 生态无缝集成
- 支持注解驱动的实体映射
兼容规则
只有小版本兼容,大版本需保持一致。
1. 向前兼容(Forward Compatibility)
新版客户端能与更高版本(或同版本)的 Elasticsearch 服务器通信,而不会出现协议层面的中断。
举例说明:
- 你有一个用 Java Client 8.12 编写的应用程序。
- 你可以将后端的 Elasticsearch 服务器从 8.12 升级到 8.13、8.14,甚至未来的 8.99。
- 你的应用程序仍然能够连接*到这些新版本的服务器,并执行基本的操作(如索引文档、执行标准查询)。
2. 新功能需要新客户端(New Features Require New Client)
举例说明:
- Elasticsearch 8.13 服务器引入了一个全新的、很酷的
awesome_searchAPI。 - 你的应用程序使用的是 Java Client 8.12。
- 虽然你的应用能连接到 8.13 服务器,但你在代码里无法调用
awesome_searchAPI,因为client.awesomeSearch()这个方法在 8.12 版本的客户端 JAR 包里根本不存在。 - 你必须将客户端依赖升级到 8.13 版本,才能在你的代码中使用这个新 API。
客户端推荐
JDK8
大家使用JDK8的话,springboot基本上都是2.x的版本,那么推荐Spring Boot 2.7.x。
Spring Boot 2.7.x -> Spring Data Elasticsearch 4.4.x -> Elasticsearch High Level REST Client 7.17.x
兼容性: 1、与ES 7.x服务器:完全兼容。
2、与ES 8.x服务器,可以通过兼容性的配置去解决能完成基本功能,但是慎用。
同时我找到了之前的github上的。 GitHub - 4.4.x 中的 spring-projects/spring-data-elasticsearch

JDK8与ES8.X的服务器兼容性处理
1. 在 pom.xml中排除默认依赖并添加新客户端:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
<exclusions>
<!-- 排除旧的低级和高级客户端 -->
<exclusion>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</exclusion>
<exclusion>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- 添加Elasticsearch官方Java API Client -->
<dependency>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
<version>8.13.0</version> <!-- 版本尽量与ES服务器一致 -->
</dependency>
<!-- 新客户端需要依赖jackson和json -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
<dependency>
<groupId>jakarta.json</groupId>
<artifactId>jakarta.json-api</artifactId>
<version>2.0.1</version>
</dependency>2. 编写Java配置类来手动创建客户端Bean
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.json.jackson.JacksonJsonpMapper;
import co.elastic.clients.transport.ElasticsearchTransport;
import co.elastic.clients.transport.rest_client.RestClientTransport;
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.elasticsearch.client.RestClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ElasticsearchConfig {
@Bean
public ElasticsearchClient elasticsearchClient() {
// 1. 如果有安全认证,配置认证信息(ES 8.x默认开启)
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY,
new UsernamePasswordCredentials("elastic", "your_password"));
// 2. 创建底层Low Level Rest Client
RestClient restClient = RestClient.builder(
new HttpHost("localhost", 9200, "https"))
.setHttpClientConfigCallback(httpClientBuilder -> httpClientBuilder
.setDefaultCredentialsProvider(credentialsProvider)
// 开发环境可以忽略SSL证书验证(生产环境切勿这样做!)
.setSSLHostnameVerifier((hostname, session) -> true)
)
.build();
// 3. 使用Jackson映射器创建Transport层
ElasticsearchTransport transport = new RestClientTransport(
restClient, new JacksonJsonpMapper());
// 4. 创建真正的API客户端
return new ElasticsearchClient(transport);
}
}3.使用 ElasticsearchClient
可以在你的Service或Repository中注入 ElasticsearchClient,并使用其现代化的API来操作ES。
@Autowired
private ElasticsearchClient client;
public void someMethod() throws IOException {
SearchResponse<SomeEntity> response = client.search(s -> s
.index("your-index")
.query(q -> q
.match(t -> t
.field("name")
.query("张三")
)
),
SomeEntity.class); // 支持直接序列化为POJO
...
}JDK17+
兼容性官网链接
Versions :: Spring Data Elasticsearch
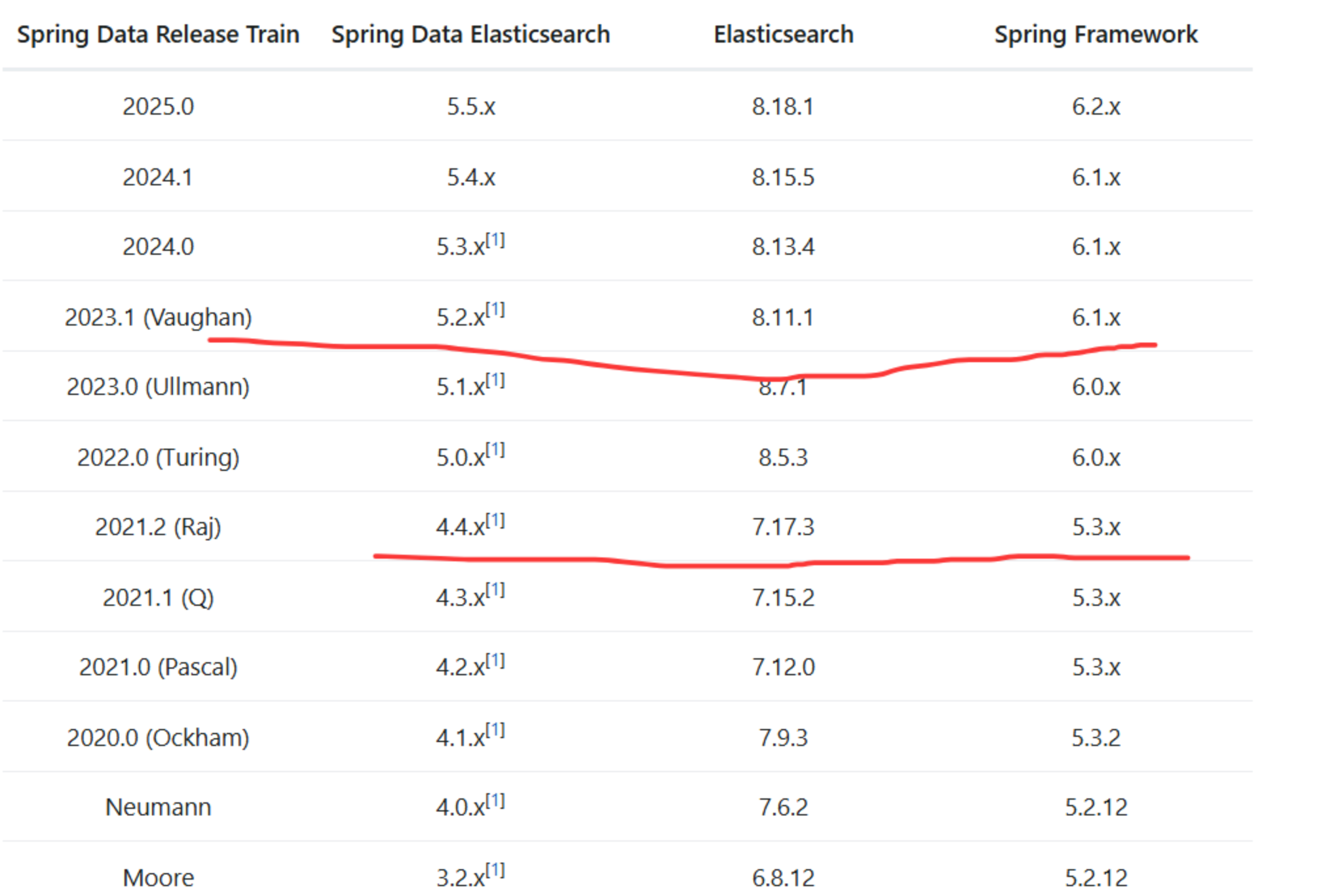
推荐使用: Spring Boot 3.2.0 -> Spring Data Elasticsearch 5.2.0 -> Elasticsearch Java API Client 8.11.1
向前兼容:根据 Elasticsearch 的策略,8.11.1 的客户端可以与更高版本的 ES 8.x 服务器(如 8.12.0, 8.13.0)进行通信和基本操作,但无法使用新版本服务器引入的新特性。
向后兼容无保证:虽然 8.11.x 客户端可能能连接 8.10.x 或更旧的 8.x 服务器,但是官网上没有说不出问题,这种是不推荐的。
2、ES客户端实战
环境准备
**操作系统:**win11,12核16GB
**JDK:**JDK17
**ES版本:**elasticsearch-8.11.1-windows-x86_64 下载地址:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.11.1-windows-x86_64.zip
找到解压后的目录:
编辑加入以下信息,关闭掉SSL之类的,方便运行和测试。
# 允许外部 IP 访问 HTTP API
network.host: 0.0.0.0
# 设置 HTTP 端口(默认为 9200)
http.port: 9200
# ======================== 集群设置 ========================
# 配置集群名称(可选)
cluster.name: my-es-cluster
# 配置节点名称(可选)
node.name: node-1
# 配置主节点初始列表(单机模式设为自身)
cluster.initial_master_nodes: ["node-1"]
# ======================== 安全设置 (开发环境可禁用) ========================
# 禁用安全功能(包括密码和 HTTPS)
xpack.security.enabled: false
# 禁用 HTTPS
xpack.security.http.ssl:
enabled: false
# 禁用传输层 SSL
xpack.security.transport.ssl:
enabled: false
# ======================== 跨域设置 (便于 Kibana 或 DevTools 访问) ========================
http.cors.enabled: true
http.cors.allow-origin: "*"ES中文分词器:
https://release.infinilabs.com/analysis-ik/stable/
解压 ik 分词器 将下载的 ik 分词器压缩包解压缩到 Elasticsearch 安装目录下的 plugins/analysis-ik 目录中。如果该目录不存在,则需要手动创建。
重启 Elasticsearch 解压完成后,需要重启 Elasticsearch 才能加载 ik 分词器
访问:
localhost:9200/_cat/plugins?v出现以下信息说明中文分词器安装成功:

**代码编辑工具:**IntelliJ IDEA 2023.2.4 (Ultimate Edition)
**数据库:**MySQL5.7/8
项目核心版本: Spring Boot 3.2.0 -> Spring Data Elasticsearch 5.2.0 -> Elasticsearch Java API Client 8.11.1
数据、代码准备
具体见视频和代码/附件
实战案例与讲解
POST Spring Data操作--创建索引
POST /api/products/native/create-index
Body 请求参数
{}请求参数
| 名称 | 位置 | 类型 | 必选 | 说明 |
|---|---|---|---|---|
| body | body | object | 否 | none |
返回示例
200 Response
{}返回结果
| 状态码 | 状态码含义 | 说明 | 数据模型 |
|---|---|---|---|
| 200 | OK | none | Inline |
返回数据结构
DELETE 原生API操作--索引删除
DELETE /api/products/native/delete-index
返回示例
200 Response
{}返回结果
| 状态码 | 状态码含义 | 说明 | 数据模型 |
|---|---|---|---|
| 200 | OK | none | Inline |
返回数据结构
GET 原生API操作--索引是否存在
GET /api/products/native/exists
返回示例
200 Response
{}返回结果
| 状态码 | 状态码含义 | 说明 | 数据模型 |
|---|---|---|---|
| 200 | OK | none | Inline |
返回数据结构
POST 原生API操作--插入单条数据
POST /api/products/native
Body 请求参数
{
"id": 666,
"name": "华为Mate60 Pro智能手机",
"description": "搭载麒麟9000S芯片,支持卫星通信的新一代旗舰手机",
"count": 100,
"price": 6999.99,
"date": "2023-08-29",
"isDeleted": false,
"tags": [
"智能手机",
"华为",
"旗舰机"
]
}请求参数
| 名称 | 位置 | 类型 | 必选 | 说明 |
|---|---|---|---|---|
| body | body | object | 否 | none |
返回示例
200 Response
{}返回结果
| 状态码 | 状态码含义 | 说明 | 数据模型 |
|---|---|---|---|
| 200 | OK | none | Inline |
返回数据结构
POST 原生API操作--批量插入
POST /api/products/native/bulk
返回示例
200 Response
{}返回结果
| 状态码 | 状态码含义 | 说明 | 数据模型 |
|---|---|---|---|
| 200 | OK | none | Inline |
返回数据结构
PUT 原生API操作--修改指定id数据
PUT /api/products/native/
Body 请求参数
{
"id": 666,
"name": "华为Mate60 Pro智能手机",
"description": "搭载麒麟9000S芯片,支持卫星通信的新一代旗舰手机",
"count": 100,
"price": 16999.99,
"date": "2025-08-29",
"isDeleted": false,
"tags": [
"智能手机",
"华为",
"旗舰机"
]
}请求参数
| 名称 | 位置 | 类型 | 必选 | 说明 |
|---|---|---|---|---|
| id | path | string | 是 | none |
| body | body | object | 否 | none |
返回示例
200 Response
{}返回结果
| 状态码 | 状态码含义 | 说明 | 数据模型 |
|---|---|---|---|
| 200 | OK | none | Inline |
返回数据结构
GET 原生API操作--根据ID查询
GET /api/products/native/
请求参数
| 名称 | 位置 | 类型 | 必选 | 说明 |
|---|---|---|---|---|
| id | path | string | 是 | none |
返回示例
200 Response
{}返回结果
| 状态码 | 状态码含义 | 说明 | 数据模型 |
|---|---|---|---|
| 200 | OK | none | Inline |
返回数据结构
GET 原生API操作--根据关键字全文检索
GET /api/products/native/search
请求参数
| 名称 | 位置 | 类型 | 必选 | 说明 |
|---|---|---|---|---|
| keyword | query | string | 否 | none |
返回示例
200 Response
{}返回结果
| 状态码 | 状态码含义 | 说明 | 数据模型 |
|---|---|---|---|
| 200 | OK | none | Inline |
返回数据结构
GET 原生API操作--按价格范围搜索
GET /api/products/native/price-range
请求参数
| 名称 | 位置 | 类型 | 必选 | 说明 |
|---|---|---|---|---|
| min | query | string | 否 | none |
| max | query | string | 否 | none |
返回示例
200 Response
{}返回结果
| 状态码 | 状态码含义 | 说明 | 数据模型 |
|---|---|---|---|
| 200 | OK | none | Inline |
返回数据结构
DELETE Spring Data操作--索引删除
DELETE /api/products/spring-data/delete-index
返回示例
200 Response
{}返回结果
| 状态码 | 状态码含义 | 说明 | 数据模型 |
|---|---|---|---|
| 200 | OK | none | Inline |
返回数据结构
GET Spring Data操作--索引是否存在
GET /api/products/spring-data/exists
返回示例
200 Response
{}返回结果
| 状态码 | 状态码含义 | 说明 | 数据模型 |
|---|---|---|---|
| 200 | OK | none | Inline |
返回数据结构
POST Spring Data操作--插入单条数据
POST /api/products/spring-data
Body 请求参数
{
"id": 777,
"name": "华为Mate60 Pro智能手机",
"description": "搭载麒麟9000S芯片,支持卫星通信的新一代旗舰手机",
"count": 100,
"price": 6999.99,
"date": "2023-08-29",
"isDeleted": false,
"tags": [
"智能手机",
"华为",
"旗舰机"
]
}请求参数
| 名称 | 位置 | 类型 | 必选 | 说明 |
|---|---|---|---|---|
| body | body | object | 否 | none |
返回示例
200 Response
{}返回结果
| 状态码 | 状态码含义 | 说明 | 数据模型 |
|---|---|---|---|
| 200 | OK | none | Inline |
返回数据结构
POST Spring Data操作--批量插入
POST /api/products/spring-data/bulk
返回示例
200 Response
{}返回结果
| 状态码 | 状态码含义 | 说明 | 数据模型 |
|---|---|---|---|
| 200 | OK | none | Inline |
返回数据结构
PUT Spring Data操作--修改指定id数据
PUT /api/products/spring-data/
Body 请求参数
{
"id": 777,
"name": "华为Mate60 Pro智能手机",
"description": "搭载麒麟9000S芯片,支持卫星通信的新一代旗舰手机",
"count": 100,
"price": 18888.88,
"date": "2025-08-29",
"isDeleted": false,
"tags": [
"智能手机",
"华为",
"旗舰机",
"遥遥领先"
]
}请求参数
| 名称 | 位置 | 类型 | 必选 | 说明 |
|---|---|---|---|---|
| id | path | string | 是 | none |
| body | body | object | 否 | none |
返回示例
200 Response
{}返回结果
| 状态码 | 状态码含义 | 说明 | 数据模型 |
|---|---|---|---|
| 200 | OK | none | Inline |
返回数据结构
GET Spring Data操作--根据ID查询
GET /api/products/spring-data/
请求参数
| 名称 | 位置 | 类型 | 必选 | 说明 |
|---|---|---|---|---|
| id | path | string | 是 | none |
返回示例
200 Response
{}返回结果
| 状态码 | 状态码含义 | 说明 | 数据模型 |
|---|---|---|---|
| 200 | OK | none | Inline |
返回数据结构
GET Spring Data操作--根据关键字全文检索
GET /api/products/spring-data/search
请求参数
| 名称 | 位置 | 类型 | 必选 | 说明 |
|---|---|---|---|---|
| keyword | query | string | 否 | none |
返回示例
200 Response
{}返回结果
| 状态码 | 状态码含义 | 说明 | 数据模型 |
|---|---|---|---|
| 200 | OK | none | Inline |
返回数据结构
GET Spring Data操作--按价格范围搜索
GET /api/products/spring-data/price-range
请求参数
| 名称 | 位置 | 类型 | 必选 | 说明 |
|---|---|---|---|---|
| min | query | string | 否 | none |
| max | query | string | 否 | none |
返回示例
200 Response
{}返回结果
| 状态码 | 状态码含义 | 说明 | 数据模型 |
|---|---|---|---|
| 200 | OK | none | Inline |
返回数据结构
GET Spring Data操作--按标签搜索
GET /api/products/spring-data/tags
请求参数
| 名称 | 位置 | 类型 | 必选 | 说明 |
|---|---|---|---|---|
| tags | query | string | 否 | none |
返回示例
200 Response
{}返回结果
| 状态码 | 状态码含义 | 说明 | 数据模型 |
|---|---|---|---|
| 200 | OK | none | Inline |
返回数据结构
同步ES数据。
以下是几种常见的同步方式,我会结合 Java 技术栈进行说明:
1. 应用层双写 (Dual Write)
这是最直接但也最不推荐的方式。
•机制:在业务代码中,当执行数据库的增删改操作时,在同一事务中或之后立即执行对 ES 的相应写操作(索引、更新、删除文档)。
•Java 技术栈:
- •Spring Boot + Spring Data JPA / MyBatis
- •Spring Boot + Spring Data Elasticsearch 或 Java REST Client
•优点:
- **•**实现简单,逻辑直观。
- **•**延迟极低,几乎是实时的。
•缺点:
- •数据不一致风险高:这是最大的问题。如果写数据库成功但写 ES 失败(网络抖动、ES 集群异常等),会导致数据不一致。虽然可以通过“先写数据库,成功后写 ES”并在失败时重试或记录日志来缓解,但无法保证 100% 的最终一致性,增加了系统的复杂性。
- •耦合性高:业务代码与数据同步逻辑紧密耦合,不利于维护。
- •性能影响:同步写操作会增加 API 的响应时间。
•适用场景:对一致性要求不高、数据量小、可以接受少量数据丢失的简单应用。生产环境通常不推荐作为主要方案。
2. 基于 Binlog 的增量同步 (CDC - Change Data Capture)
这是目前最主流、最推荐的生产级方案。其核心是伪装成一个 MySQL 从库,实时监听并解析主库的 binlog,获取数据变更,然后将这些变更应用到 ES 中。
•机制:
- **1.**工具订阅 MySQL 的 binlog。
- **2.**当 MySQL 有数据变更时,binlog 会记录这些变更。
- **3.**工具解析 binlog,将其转换为可读的结构化数据(或直接转换为 ES 文档格式)。
- **4.**工具将转换后的数据推送到 ES。
•Java 技术栈 (常用工具):
- •Canal: 阿里开源的纯 Java 编写的 CDC 工具。需要自己编写客户端(同样是 Java)来接收 Canal 解析的数据并写入 ES。社区生态丰富,与 Java 技术栈集成非常自然。
- •Debezium: 另一个强大的开源 CDC 平台,基于 Kafka Connect 构建。它将 binlog 变更捕获为事件流(通常发送到 Kafka),然后由其他 Connector(如 ES Sink Connector)消费并写入 ES。虽然是 Java 开发的,但对用户来说是更通用的解决方案。
•优点:
- •解耦:与业务代码完全分离,对应用透明,不侵入业务逻辑。
- •高性能:对主库压力小,延迟低(近实时)。
- •保证数据一致性:只要 binlog 不丢失,就能最终保证数据同步的一致性。
•缺点:
- •架构更复杂:需要部署和维护额外的组件(Canal/Dezebium、可能还需要 Kafka)。
- •有学习成本:需要理解 binlog 和这些工具的工作原理。
•适用场景:几乎所有生产环境,特别是对数据一致性和实时性要求高的中大型项目。
3. 异步消息队列解耦
这种方式是双写模式的优化版,通过引入消息队列来解耦和削峰,保证最终一致性。
•机制:
- **1.**业务代码成功写入数据库后,发送一条消息到 MQ,然后立即返回。
- **2.**一个独立的消费者服务监听 MQ,收到消息后执行对 ES 的写操作。
- **3.**如果写 ES 失败,MQ 的消息重试机制可以保证任务被重新消费。
•Java 技术栈:
- •Spring Boot + Spring Data JPA / MyBatis (写 DB 和发消息)
- •Spring Boot + Spring Data Elasticsearch (消费消息和写 ES)
- •消息中间件: RabbitMQ, RocketMQ, Kafka
•优点:
- •解耦:业务层与同步层分离。
- •最终一致性:利用 MQ 的可靠性保证,最终数据会同步成功。
- •削峰填谷:MQ 可以缓冲瞬时流量,对 ES 起到保护作用。
•缺点:
- •依然有一定侵入性,需要在业务代码中发消息。
- **•**延迟比双写略高,但通常可以接受。
- **•**需要额外维护 MQ 组件。
•适用场景:已经使用了 MQ 的系统,作为对 CDC 方案的一种替代或补充。
4. 全量/增量拉取 (定时任务或日志扫描)
•机制:
- •全量同步:编写一个独立的 Job,定期(例如每天凌晨)扫描整个 MySQL 表,将数据全部导入 ES。通常用于初始化或数据重建。
- •增量同步:在表中设计一个类似
update_time的字段,定时任务周期性查询update_time大于上次执行时间的记录,同步这些增量数据到 ES。
•Java 技术栈:
- •Spring Boot + Spring Scheduler (
@Scheduled) - •Elasticsearch REST Client 或 Spring Data Elasticsearch
- •Quartz (更强大的定时任务框架)
- •Spring Boot + Spring Scheduler (
•优点:
- **•**实现简单,无需复杂组件。
•缺点:
- •延迟高:数据同步延迟取决于定时任务的执行间隔。
- •有重复计算:增量同步依赖于
update_time,如果该字段未及时更新或记录有误,会导致数据同步不准确或遗漏。 - •对数据库有压力:全量同步或扫描大表时可能影响数据库性能。
•适用场景:
- •全量同步:主要用于首次构建 ES 索引或索引重建。
- •增量同步:仅适用于对实时性要求非常低(分钟级或小时级)的场景。
总结与建议
| 方式 | 实时性 | 一致性 | 耦合性 | 复杂度 | 推荐度 |
|---|---|---|---|---|---|
| 应用层双写 | 极高 | 弱 | 高 | 低 | ⭐ (不推荐) |
| Binlog CDC | 高 (近实时) | 强 (最终) | 无 | 高 | ⭐⭐⭐⭐⭐ (首选) |
| MQ 解耦 | 高 | 强 (最终) | 中 | 中 | ⭐⭐⭐⭐ |
| 定时拉取 | 低 | 中 | 无 | 低 | ⭐⭐ (仅限特定场景) |
给 Java 后端开发者的建议:
- 1.首选方案:对于新项目或系统重构,强烈推荐使用 Binlog CDC 模式。在 Java 技术栈下,Canal 是一个自然且成熟的选择。你可以使用
canal-deploy服务端解析 binlog,然后自己编写一个 Canal Java 客户端来接收数据并调用 ES 的 API 进行写入。社区也有不少 Spring Boot 集成的例子。 - 2.备用方案:如果系统已经大量使用消息队列(如 Kafka),可以考虑采用 Debezium + Kafka Connect 的方案,这更像一个企业级的标准化流水线。
- 3.初始化工具:无论选择哪种增量方案,在第一次建立 ES 索引时,都需要一个全量同步工具。可以用 Java 写一个简单的批处理任务,从 MySQL 批量查询数据并批量写入(Bulk API)ES。
- 4.避免使用:尽量避免在核心业务代码中直接使用双写,除非你能很好地处理各种异常情况并接受可能的数据不一致。
最终,技术选型需要根据你的团队技术储备、项目规模、实时性要求和运维能力来综合决定。但对于大多数严肃的生产系统,基于 Binlog 的 CDC 是毋庸置疑的最佳实践。
如何使用 DataX 进行同步?
DataX 实现同步有两种方式:
1. 全量同步 (Full Sync)
这是 DataX 最经典、最擅长的模式。你编写一个 JSON 配置文件,指定要读取的 MySQL 表和要写入的 ES 索引,然后运行 DataX 任务即可。
示例配置片段:
<pre class="ybc-pre-component ybc-pre-component_not-math"><div class="hyc-common-markdown__code"><div class="expand-code-width-placeholder"></div><div class="hyc-common-markdown__code__hd"></div><pre class="hyc-common-markdown__code-lan"><div class="hyc-code-scrollbar"><div class="hyc-code-scrollbar__view"><code class="language-json">{ "job": { "content": [ { "reader": { "name": "mysqlreader", "parameter": { "username": "your_username", "password": "your_password", "column": ["id", "name", "age", "update_time"], "connection": [ { "table": ["your_table"], "jdbcUrl": ["jdbc:mysql://your_mysql_host:3306/your_db"] } ] } }, "writer": { "name": "elasticsearchwriter", "parameter": { "endpoint": "http://your_es_host:9200", "accessId": "your_user", "accessKey": "your_password", "index": "your_index", "type": "_doc", "cleanup": true, "settings": { "index": { "number_of_shards": 1, "number_of_replicas": 0 } }, "discovery": false, "batchSize": 1000, "splitter": "," } } } ], "setting": { "speed": { "channel": 3 } } } }</code></div><div class="hyc-code-scrollbar__track"><div class="hyc-code-scrollbar__thumb"></div></div><div><div></div></div></div></pre></div></pre>
2. 模拟增量同步 (Simulated Incremental Sync)
通过业务上的技巧,DataX 可以实现定时批量的增量同步。
•原理:在 MySQL 表中设计一个
update_time或create_time字段,记录数据的更新时间。•方法:在 DataX 的 MySQL Reader 配置中,使用
where条件来指定只同步一段时间内更新的数据。<pre class="ybc-pre-component ybc-pre-component_not-math"><div class="hyc-common-markdown__code"><div class="expand-code-width-placeholder"></div><div class="hyc-common-markdown__code__hd"></div><pre class="hyc-common-markdown__code-lan"><div class="hyc-code-scrollbar"><div class="hyc-code-scrollbar__view"><code class="language-json">"reader": { "name": "mysqlreader", "parameter": { ... "where": "update_time >= '2023-10-27 00:00:00'", ... } }</code></div><div class="hyc-code-scrollbar__track"><div class="hyc-code-scrollbar__thumb"></div></div><div><div></div></div></div></pre></div></pre>
•流程:
- **1.**编写一个脚本,记录上次同步的时间点 T。
- **2.**定时(例如每 5 分钟)触发 DataX 任务,配置
where条件为update_time >= T。 - **3.**同步完成后,将时间点 T 更新为当前时间。
- **4.**等待下一次触发。
DataX 方案的优缺点分析
| 优点 | 缺点 |
|---|---|
| ✅简单易用:配置化,无需编写大量代码。 | ❌非实时:延迟高,取决于同步任务的执行间隔(分钟级/小时级)。 |
| ✅性能强大:内置通道、批量、流控等机制,全量同步速度快。 | ❌数据库压力:每次查询都是对 MySQL 的一次 SELECT扫描,如果表大且频繁查询,对源库有压力。 |
| ✅稳定可靠:阿里开源,久经考验,社区活跃。 | ❌可能漏数据:如果数据在两次任务间隔期间被更新并再次更新回原值,update_time无法捕捉到这种变化,会导致数据同步遗漏。 |
| ✅与技术栈无关:作为独立进程运行,对 Java 应用本身无侵入。 | ❌不能同步删除:如果记录在 MySQL 中被物理删除,基于 where update_time的方案无法感知和同步删除 ES 中的对应文档。通常只能逻辑删除。 |
| ✅适合全量初始化:是做索引预构建和数据重建的绝佳工具。 | ❌运维成本:需要额外维护一套定时调度系统(如 Linux Cron, Apache Airflow, DolphinScheduler)来驱动增量任务。 |
结论与建议
•DataX 能实现 MySQL 到 ES 的同步吗?
能。它是一个非常出色的全量数据迁移和批量离线同步工具。
•DataX 应该用在什么地方?
- 1.初始建索引:在项目上线前,一次性将历史 MySQL 数据全部导入 ES。
- 2.索引重建:当 ES 索引映射(Mapping)发生重大变更或数据出现严重不一致时,用于全量重建索引。
- 3.对实时性要求极低的场景:例如只需要每天凌晨同步一次数据的离线报表、分析系统。
•DataX 不应该用在什么地方?
不建议将其作为生产系统中唯一的、主要的实时增量同步方案。对于需要近实时搜索(延迟在秒级/毫秒级)的业务场景,Binlog CDC(Canal/Debezium)才是更专业、更推荐的选择。
最佳实践:
结合使用两者,发挥各自优势。
- •使用 DataX 进行第一次全量数据同步。
- •使用 Canal 或 Debezium 进行后续的实时增量同步。
- **•**如果未来需要重建索引,再次使用 DataX 进行全量同步,然后让 Binlog CDC 继续接管增量任务。